







Why Healthcare AI Pilots Fail (Simple Answer)
Healthcare AI pilot projects fail because they are not built for real-world conditions. Despite strong pilot results, the transition to production exposes gaps that controlled environments never surface.
In most hospital systems, integration, data pipelines, and MLOps account for approximately 70% of all production failures. The remaining 30% comes from compliance delays, change management breakdowns, and cost miscalculations. Understanding which category your initiative falls into determines where to act first.
The most common failure reasons are:
Lack of integration with legacy hospital systems
Poor data quality and unreliable production pipelines
No MLOps infrastructure for continuous model performance
Workflow misalignment with frontline clinicians
Regulatory and compliance gaps that research exemptions temporarily masked
This answer is straightforward. The complexity lies in how deeply each of these failures is embedded in hospital systems and how early they need to be addressed to prevent them.
What Most Teams Get Wrong About Healthcare AI
Most teams enter AI deployments with two assumptions that consistently prove false:
Better models equal better outcomes
Pilot success means production readiness
In reality: infrastructure determines success. Architecture determines scalability.
A model that performs at 92% accuracy in a controlled trial is not a production-ready system. It is a proof of concept sitting on top of assumptions that will not hold at scale clean data, manual oversight, and a forgiving testing environment. When those assumptions disappear, so does the performance.
AI fails not at the model layer, but at the system layer.
This reframing is the single most important shift a hospital leadership team can make before committing to a production deployment.
The Promise vs. The Reality
Hospitals invest heavily in AI expecting transformative results: faster diagnostics, reduced administrative burden, predictive patient monitoring. The pilots look promising. The boardroom presentations are optimistic. And then, somewhere between a controlled trial and real-world deployment, everything stalls.
Industry data consistently shows that roughly 80% of healthcare AI pilot projects never reach production. The reasons are rarely about the AI model itself. They are almost always about what surrounds it infrastructure, workflows, governance, and organizational readiness.
Understanding healthcare AI implementation failures requires looking beyond the technology and examining the systemic gaps that separate a successful 100-case pilot from a hospital-wide rollout serving thousands of patients daily.
Pilot success measures accuracy. Production success measures reliability.
This Is Not Just an AI Problem
AI stalls in production because the product foundation beneath it was never engineered for scale.
Most hospitals assume a stalled pilot is an AI problem. It isn't.
This is a product engineering problem one that involves system architecture, data pipelines, DevOps workflows, and integration design. AI fails not because the model is wrong, but because the product foundation beneath it was never built for production.
The hospitals that scale successfully don't just build better models. They build better engineering foundations around those models with Cloud and DevOps Engineering, proper data infrastructure, and integration-first architecture designed from day one.
Key Takeaway: If the product foundation is weak, even the most accurate AI model will fail in production. Architecture decisions, not model performance, determine scalability.
Until this shift in framing happens, the same pilots will keep failing for the same reasons.
Technical Barriers That Break Production
AI fails in production mainly due to integration gaps, infrastructure limitations, and missing MLOps not model quality.
Legacy System Integration
Most hospitals run on electronic health record systems, PACS platforms, and RIS infrastructure that is often 10 to 20 years old. These systems were not designed with modern AI in healthcare interoperability in mind. They lack the APIs required to feed real-time data into AI models, and retrofitting them requires middleware layers that are expensive, time-consuming, and fragile under load.
Consider a practical example: a hospital deploying AI-assisted triage may run a clean pilot on 100 curated cases. In production, that same system processes 10,000+ patients daily with inconsistent data formats, missing fields, and real-time feeds from systems that were never designed to communicate with each other. The gap between those two environments is where most AI implementation in hospitals breaks.
The table below illustrates how these challenges in deploying AI in hospitals translate into measurable production impact:
| Barrier | Impact on Production | Mitigation Approach |
|---|---|---|
| No modern APIs | Data silos block AI input entirely | Phased middleware rollout |
| High-latency legacy hardware | Real-time inference fails under volume | Cloud bursting for compute |
| Inconsistent data formats | Model accuracy drops 20–30% | Standardization pipelines |
These failures happen not because the AI is poorly designed, but because AI is added without the foundational product engineering layers cloud architecture, DevOps workflows, and data design that production demands.
Key Takeaway: If your AI system cannot integrate with legacy EHRs, it will not scale regardless of model accuracy.
If your hospital systems still rely on legacy infrastructure without modern APIs, this is almost always where AI initiatives break first. An early architecture review can identify these risks before they become production failures typically saving 6–9 months of rework.
Model Drift and the MLOps Gap
A model that isn't continuously monitored and retrained is a model that's silently degrading.
Even when integration is handled correctly, models degrade. Patient demographics shift seasonally. Clinical protocols evolve. Data entry habits change across departments. What was 92% accurate during a pilot quietly erodes to 78% in production over six to twelve months.
AI models are not products. They are continuously evolving systems.
Addressing this requires continuous retraining pipelines, real-time monitoring, and version-controlled deployment infrastructure what the industry refers to as MLOps. Most pilots are built without any of this. The assumption is that a model trained once will perform indefinitely. In healthcare, that assumption is consistently wrong and sometimes dangerous.
Organizational Roadblocks
Workflow Misalignment
Clinicians don't reject AI because it's inaccurate. They reject it because it adds friction.
Clinicians have one overriding priority: patient care. Any AI tool that adds steps, generates alert fatigue, or interrupts established routines will be ignored regardless of its technical accuracy. This is one of the most documented AI adoption barriers in hospitals, and it is almost entirely preventable.
The solution is designing AI to be invisible within existing workflows. Auto-populating fields, surfacing insights within tools clinicians already use, and reducing cognitive load rather than adding to it. This requires clinician co-design from the very first prototype a core principle of structured Product Design and Prototyping not as an afterthought after the model is built.
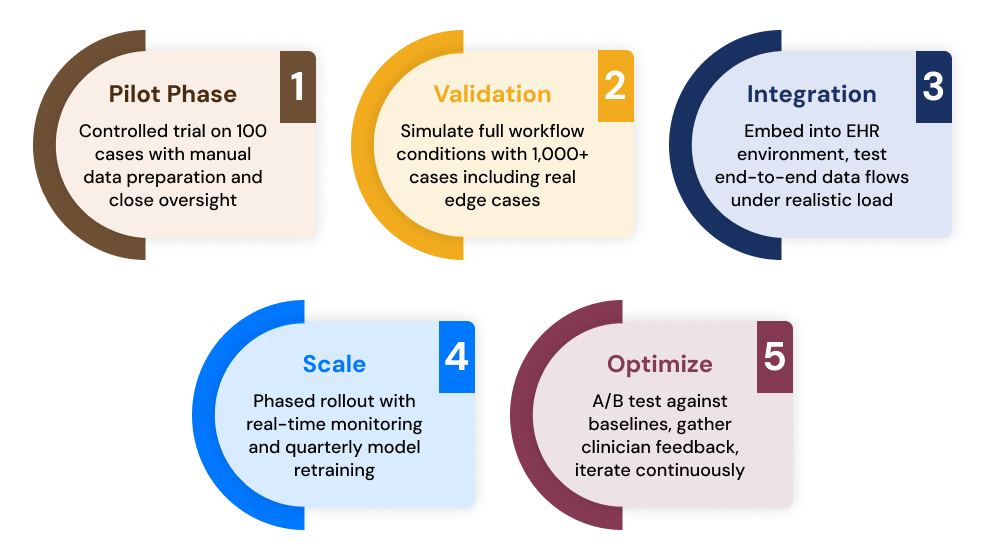
Each stage requires feedback loops that feed back into previous stages. Skipping validation is the single most common reason healthcare AI pilot failure occurs at the integration phase.
Change Management: The Human Variable
The most technically complete AI deployment will fail if the people using it were never brought along.
Pilots excite executives. They do not automatically excite the nurses, radiologists, and administrative staff who will actually use the system every day. Without structured change management training programs, internal champions, and transparent communication about what the AI does and does not do adoption rates collapse post-launch.
This is the dimension responsible for a significant share of AI pilot failures: not a technology shortcoming, but a people and process gap. Stakeholder buy-in must be built around clear ROI metrics that map to the incentives of each user group, not just the C-suite.
Product Strategy & Consulting plays a critical role here. Early stakeholder alignment work, conducted before a single line of model code is written, determines whether a deployment succeeds or becomes a cautionary case study.
Regulatory and Ethical Complexity
Compliance gaps discovered at the production stage don't just slow things down they can stop a deployment entirely.
The Compliance Gap Between Pilot and Production
Pilots in academic or research settings often operate under exemptions that do not apply to commercial deployment. A model used in production to assist clinical decision-making may require FDA 510(k) pre-market notification, adding 18 to 24 months to the timeline. HIPAA compliance moves from a de-identified data consideration to a full audit requirement. In EU contexts, GDPR mandates a Data Protection Impact Assessment for high-risk AI systems.
| Regulation | Pilot Tolerance | Production Requirement |
|---|---|---|
| HIPAA | Waived for de-identified data | Full compliance audits |
| FDA 510(k) | Not enforced in research context | Pre-market notification required |
| GDPR (EU) | Minimal oversight | DPIA for high-risk AI classification |
These are not insurmountable obstacles, but they are non-negotiable ones. Governance cannot be bolted on at the end of a development cycle. Ethics reviews, bias audits, and compliance documentation must be embedded into the development process from the earliest stages reducing the risk of an 18-month regulatory delay that kills organizational momentum entirely.
Bias and Trust Erosion
Models trained on non-representative datasets underperform on underrepresented patient populations. When this surfaces in production, it doesn't just create a technical problem it creates a trust problem that sets back healthcare AI adoption challenges across entire institutions. Diverse, representative training data and continuous bias monitoring are core infrastructure requirements, not optional enhancements.
Data and Infrastructure Realities
You cannot build a production-grade AI system on top of fragmented, ungoverned data.
Hospitals accumulate data across decades and departments, but that data is almost never unified or production-ready. Siloed systems, inconsistent labeling, and departmental data ownership disputes create an environment where even excellent models have nothing reliable to train on or inference against.
Addressing this requires building secure, governed data lakes with clear lineage and access controls. Software Product Development practices modular architecture, API-first design, separation of data and application layers provide the structural foundation that most hospital-built AI systems lack.
This is where Cloud and DevOps Engineering within product engineering becomes critical enabling scalable deployment, real-time monitoring, containerized model delivery using Kubernetes, and auto-scaling inference that on-premises infrastructure simply cannot support.
Key Takeaway: Data infrastructure is not a prerequisite you address before AI. It is the foundation you build AI on top of. Get this wrong and every other investment compounds the error.
The Cost Reality No Pilot Budget Accounts For
The financial gap between pilot and production is not a rounding error it is a magnitude shift.
The financial arithmetic of AI deployment in healthcare is consistently misunderstood at the pilot stage.
| Cost Category | Pilot Estimate | Production Reality |
|---|---|---|
| Development | $200K | $2M+ with full integration |
| Annual Maintenance | Negligible in pilot | $500K per year |
| Staff Training | $10K | $300K across clinical staff |
Pilots typically cost between $100K and $500K. Production deployments with full integration, security, compliance, and ongoing operations routinely reach $5M or more. Organizations that discover this after committing to a rollout either abandon the initiative or under-resource it both outcomes guarantee failure.
Hidden costs include model retraining, which typically consumes 20% of the annual AI budget, and vendor lock-in from proprietary pilot tools that don't scale without expensive migrations.
A structured product engineering approach applied during the pilot phase identifies these gaps early reducing rework, avoiding failed rollouts, and cutting total cost of ownership by 30–40% while accelerating production timelines by 6–12 months.
Most teams discover these cost realities after budgets are committed and timelines are locked. A production readiness assessment during the pilot phase is consistently the highest-ROI intervention available at that stage.
Quick Decision Guide: What Should You Do Next?
The right action depends entirely on where your initiative currently stands.
| Your Situation | Immediate Action | What You Avoid |
|---|---|---|
| Systems are legacy-heavy | Architecture audit before any model development | 12+ months of integration rework |
| Data is scattered across departments | Fix data pipelines before investing in AI | Model accuracy collapse in production |
| Currently in pilot phase | Add MLOps infrastructure now | Silent model drift post-launch |
| Pilot succeeded but production stalled | Audit integration architecture and compliance posture | Sunk cost on a stalled rollout |
| Budget is uncertain | Map hidden production costs before committing to scale | Budget overruns that kill momentum |
What Separates Hospitals That Scale Successfully
The difference between stalled pilots and successful deployments comes down to engineering foundations, not model sophistication.
| Success Factor | Example | Outcome |
|---|---|---|
| Clinician Co-Design | Mayo Clinic AI development labs | 70% adoption rate post-launch |
| Centralized AI Governance | Johns Hopkins AI center model | Successfully scaled 5 pilots to production |
| Vendor Ecosystem Integration | AWS Health AI partnerships | Production deployment within 6 months |
The pattern across successful deployments is consistent: early investment in product foundations, clinician involvement from the prototype stage, and treating AI not as a standalone technology project but as a Software Product Development initiative with all the disciplines that entails architecture, DevOps, data engineering, and change management working in parallel.
Case Studies: Failure and Success in Contrast
The NHS experience represents one of the most documented examples of healthcare AI pilot failure at scale: approximately 80% of pilots were ultimately abandoned, with legacy EHR incompatibility cited as the primary barrier. The tools were technically sound. The infrastructure was not ready. No amount of model refinement would have changed that outcome.
In contrast, GE Healthcare's radiology AI platform scaled successfully by prioritizing API-first architecture from day one, ensuring that integration with existing PACS systems was a design requirement rather than a post-development problem.
A US hospital system applied structured healthcare AI implementation practices to a sepsis prediction model. The pilot achieved 92% accuracy. By investing in MLOps infrastructure before scaling rather than after production accuracy held at 88% across a full patient population. That 4-point difference, maintained at production volume, represents the difference between a clinical tool that gets used and one that gets abandoned.
Final Takeaways
AI pilots fail due to system gaps, not model issues the model is rarely the problem
Integration, data pipelines, and MLOps are the three biggest blockers accounting for roughly 70% of production failures
Costs increase 5–10x post-pilot organizations that don't model this early run out of budget at the worst possible moment
Compliance delays are unavoidable without early planning 18–24 months of regulatory lag can be compressed significantly with the right governance framework built in from the start
Product engineering determines whether AI scales or stalls architecture decisions made in the pilot phase set the ceiling for everything that follows
Is Your AI Pilot Actually Production-Ready?
If your AI initiative is still stuck between validation and production, the issue is rarely the model.
Most failures trace back to three places: integration gaps between AI and legacy systems, missing MLOps infrastructure for ongoing model reliability, and architecture foundations that were never designed for production scale.
These are solvable problems but they are significantly cheaper and faster to solve during the pilot phase than after a failed rollout.
A focused AI Production Readiness Assessment covers your architecture, data pipelines, DevOps gaps, and compliance posture typically identifying the specific failure points in two to three weeks, before they surface at scale and cost an order of magnitude more to fix.
Explore how structured product engineering services can help you move from pilot to production with infrastructure that holds and keeps performing once it gets there.
Move Your Healthcare AI from Pilot to Production




