







Why do fraud detection systems block legitimate transactions at high volume?
Fraud detection systems block legitimate transactions at high volume because they rely on static rules, outdated models, and simplified decision logic under latency pressure. As transaction volume increases, systems process less context per transaction leading to higher false positives in fraud detection and incorrect blocking of real users. This is where modern product engineering services play a key role in designing scalable, high-performance systems that can handle growing transaction loads without compromising accuracy.
Why This Happens in Simple Terms
When transaction volume increases, your fraud detection system is forced to make faster decisions. To keep up, it starts using fewer data points and simpler rules. This leads to more mistakes especially blocking legitimate users who behave slightly differently than usual.
Payment fraud detection is the process of analyzing transactions in real time to identify and block suspicious activity while allowing legitimate transactions to pass through without friction.
Think of it like a security guard at a stadium. At 100 people, they check every ticket carefully. At 10,000 people rushing in at once, they start stopping anyone who looks unfamiliar and that's when real customers get turned away.
Most fraud detection failures at scale are not caused by bad models they are caused by architecture that cannot handle volume.
Why Fraud Detection Systems Fail During Peak Traffic
If you're a CTO, product leader, or engineering head in fintech handling high transaction volumes, this is likely already affecting your system even if you haven't measured it yet.
Volume spikes increase false positives in fraud detection because fraud systems rely on static thresholds, historical patterns, and simplified decision logic under latency pressure. The result is a system that gets more aggressive not more accurate precisely when your transaction volumes are highest and the cost of blocking real customers is greatest.
Fraud typically represents only 0.1–1% of all transactions making models highly prone to false positives at scale.
At enterprise scale, false positives in fraud detection cost banks and fintechs over $1.5 billion annually in lost revenue, according to McKinsey's 2025 report. For a growing fintech startup, even a fraction of that impact can stall momentum and destroy hard-earned customer trust.
How a Fraud Detection System Actually Works
At its core, a fraud detection system analyzes transaction metadata in real time and assigns a risk score. If that score crosses a threshold, the transaction gets blocked, flagged for review, or approved.
A typical transaction fraud detection pipeline involves five moving parts:
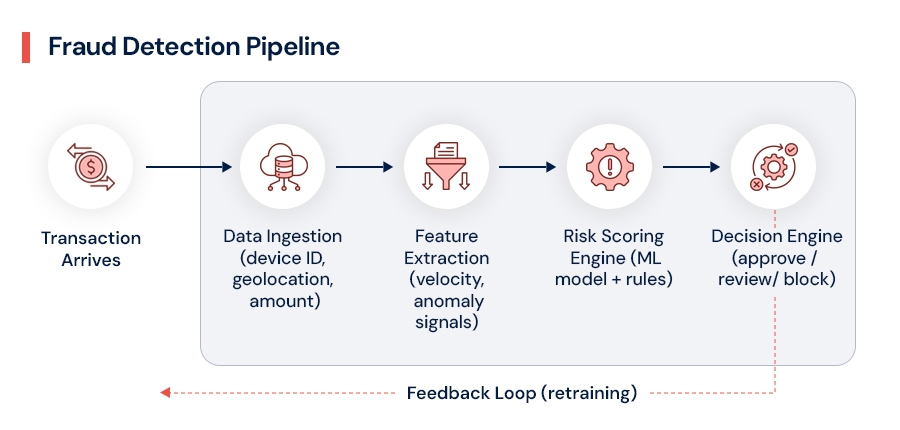
Each layer works well in isolation. Under scale, the entire chain starts to crack usually at the ingestion and scoring layers first.
Why Volume Spikes Cause More Legitimate Blocks
Volume spikes increase false positives because fraud detection systems rely on static thresholds, historical patterns, and simplified decision logic under latency pressure. Here's exactly how each failure mode plays out:
Data overload drowns out legitimate signals. When thousands of users make purchases simultaneously from new locations or devices, the system interprets normal behavior as suspicious. A user making 10 purchases during a flash sale isn't committing fraud but your static velocity rules don't know that.
Model drift quietly degrades accuracy. Fraud detection algorithms trained six months ago don't reflect today's user behavior. Post-pandemic remote shopping patterns, VPN usage, and cross-border transactions have all shifted. Without frequent retraining, models drift and false positive rates climb 20–30%.
When systems optimize for speed (sub-100ms decisions), they sacrifice accuracy increasing false positives.
Latency pressure forces shortcuts. At 10,000+ transactions per second, your scoring engine must respond in under 100ms. To meet that requirement, systems drop complex features and rely on simplified rules which are far less accurate.
Imbalanced data makes models oversensitive. Fraud accounts for only 0.1–1% of all transactions. Models trained on this imbalance tend to misclassify legitimate edge cases like a high-value wire transfer or a bulk corporate purchase as fraud.
In short: Fraud systems fail at scale due to data overload, model drift, latency constraints, and imbalanced training data.
Low-Scale vs High-Scale Fraud Detection Behavior
| Factor | Low Volume | High Volume |
|---|---|---|
| Decision speed | Slower, more accurate | Faster, less context |
| Model accuracy | Stable | Degrades (model drift) |
| Rules effectiveness | Works as intended | Over-triggers on normal behavior |
| False positives | Low | High (5–30%) |
| Feature usage | Full context per transaction | Simplified to meet latency |
How to Know If Your Fraud System Is Costing You Revenue
Most teams only discover this after revenue starts dropping. Your real-time payment fraud detection system may already be failing if you're seeing any of these signals:
False positive rate consistently above 5%
Customer complaints rising during peak traffic periods
Conversion rate drops that don't correlate with marketing changes
Manual review queues growing faster than your team can handle
Churn spikes following high-volume events
If these signals look familiar, your system is already leaking revenue during peak traffic even if it's not visible in your dashboards yet. If you're seeing even two of them, your payment fraud detection infrastructure likely has architectural gaps not just model problems.

The Algorithm Problem: Why Scaling Breaks Every Approach Differently
No single fraud detection model performs well at scale hybrid architectures combining rules, ML, and contextual intelligence are required.
Different fraud detection algorithms fail in different ways under load. Understanding this is critical for choosing the right fix.
Rule-based systems (velocity checks, geo-blocks) are fast and interpretable but completely rigid. They can't distinguish between a real fraud pattern and a legitimate volume surge. Online payment fraud detection systems that rely heavily on static rules typically see false positive rates of 15–25% at scale.
Supervised ML models like Random Forest perform well on labeled data but degrade quickly when user behavior shifts. Unsupervised models like Isolation Forest handle imbalanced datasets but become hypersensitive to outlier bursts that occur during legitimate high-volume events pushing false positive rates to 20–35% during peaks.
Deep learning models (LSTMs, Graph Neural Networks) offer the best accuracy for fraud detection at scale but demand significant compute. Without proper Cloud and DevOps Engineering infrastructure, latency spikes during high-volume events make them impractical as standalone solutions.
The takeaway: no single algorithm solves fraud detection in fintech at scale. A hybrid approach is the only architecture that holds up.
Real-World Proof: What Fixing This Looks Like
A fintech platform processing high transaction volumes reduced false positives in fraud detection by 40% after implementing graph-based AI fraud detection system logic modeling user relationship networks to contextualize volume spikes rather than flag them. The result was a measurable increase in conversion during peak traffic periods and a significant reduction in manual review costs.
Teams that invest in proper fraud detection software optimization consistently report similar outcomes. The common thread isn't a single tool or model. It's architectural maturity combined with adaptive intelligence.
What a Scalable Fraud Detection System Actually Looks Like
Building scalable fraud detection solutions isn't a single fix. It's a phased engineering investment. Here's how high-performing fintech teams approach it:
Phase 1 Audit and Strategy This typically starts with a structured evaluation through Product Strategy & Consulting, where system bottlenecks and false positive drivers are identified before any engineering work begins. Define measurable KPIs upfront: false positive rate below 5%, decision latency under 50ms, and retraining cycles measured in days, not months.
Phase 2 Hybrid Model Design Product Design and Prototyping involves building a hybrid scoring engine that combines rule-based velocity checks with ML models and graph analytics. Simulate 10x volume using load testing tools before any production deployment. This phase is where the architecture decisions that determine scale tolerance are made.
Phase 3 Scalable Infrastructure This is where Software Product Development and Cloud and DevOps Engineering come together. Kubernetes auto-scaling, multi-region replication, and microservices architecture allow your ingestion and scoring layers to scale independently during peaks without dropping features or forcing model shortcuts.
Phase 4 Adaptive Intelligence AI & Data Engineering handles the retraining pipeline. Using tools like Kafka and MLflow, models are retrained continuously on fresh transaction data. Adaptive thresholding where risk score cutoffs adjust dynamically based on current transaction volume reduces false positives by 25–40% without sacrificing fraud catch rates.
Key techniques and their impact on reducing false positives:
| Technique | Estimated Reduction | Engineering Layer |
|---|---|---|
| Auto-scaling infrastructure (Kubernetes) | ~25% | Cloud and DevOps Engineering |
| Contextual rules (user tier, history) | ~35% | Software Product Development |
| Graph neural networks (user networks) | ~40% | AI & Data Engineering |
| Federated learning across regions | ~40% | AI & Data Engineering |
| Adaptive thresholding (volume-aware) | ~30% | AI & Data Engineering |
Advanced Approaches Worth Knowing
Contextual intelligence is one of the highest-impact upgrades available in modern AI fraud detection systems. By layering user relationship graphs into the scoring engine, the system can distinguish between a new user making unusual purchases and a long-standing user experiencing a normal behavioral shift a distinction that static rules are completely blind to.
Explainable AI using SHAP values helps your team understand exactly why a transaction was flagged. This dramatically speeds up human override decisions and accelerates model improvement cycles directly reducing review queue backlogs and the cost of manual intervention.
Edge AI is emerging as the next frontier for sub-10ms real-time fraud detection, processing decisions closer to the transaction source. Combined with quantum-resistant encryption, this represents where fraud detection in fintech is heading over the next 3–5 years.
The Business Case: What Fixing This Is Actually Worth
A blocked legitimate transaction doesn't just lose you that sale. It loses you the customer. Average churn cost per blocked transaction runs $50–200 when you account for lifetime value.
The ROI math is straightforward: if your platform processes 500,000 transactions per month with a 7% false positive rate, you're blocking 35,000 legitimate transactions monthly. Even at $50 average order value, that's $1.75 million in preventable monthly revenue loss. Investing in proper fraud detection software and infrastructure optimization consistently delivers 3–5x ROI within the first year through higher throughput, lower manual review costs, and improved customer retention.
Key takeaway: If your fraud detection system isn't designed for scale, it will increasingly block legitimate customers as your volume grows directly impacting revenue.

When to Fix Fraud Detection Systems Before Revenue Loss Increases
The most common mistake fintech teams make is treating fraud detection challenges as a model problem when it's actually an infrastructure and architecture problem. Retraining your model won't fix a bottlenecked ingestion layer. Better rules won't compensate for missing auto-scaling.
If your system is already showing early signals rising complaint volumes, declining conversion during peaks, growing review queues delaying fixes will only increase revenue loss as your volume grows. The teams that solve this durably invest in three things simultaneously: adaptive AI & Data Engineering for smarter scoring, Cloud and DevOps Engineering for elastic infrastructure, and continuous feedback loops that tighten the system with every transaction cycle.
To reduce false positives in payments at scale, you need all three working together. Payment fraud detection done right is not a product you buy it's an engineering capability you build and continuously improve.
Conclusion
As transaction volumes grow, your fraud detection system will either evolve or become a liability. The false positives in fraud detection problem are solvable but only with the right architecture, the right algorithms, and the right engineering foundation underneath it all.
The fintechs winning this fight aren't the ones with the most aggressive fraud rules. They're the ones who've built fraud detection solutions intelligent enough to tell the difference between a fraudster and a loyal customer having a big shopping day. If your current system can't make that distinction reliably at scale, it's time to rebuild it with one that can.




