







Every FinTech platform reaches the same painful moment: a fraud detection model that scored 95% accuracy in testing starts hemorrhaging false positives within weeks of going live. Transactions get blocked. Customers churn. Operations teams drown in manual reviews.
The instinct is to blame the model. Retrain it. Tune the thresholds. But the real problem is almost always upstream in the data architecture that feeds the model, not the model itself.
70% of fraud detection in banking initiatives fail to deliver ROI, not because of poor data science, but because the data pipelines underneath were never designed for production reality. At scale, a 5% drop in approval rates can translate to millions in lost revenue annually for mid-sized payment platforms.
This is especially relevant for FinTech CTOs, product leaders, and engineering teams managing high-volume payment processing systems. If that sounds familiar, this guide breaks down exactly why production failures happen and what to do about it.
What Is a Payment Fraud Detection System?
A payment fraud detection system is a real-time decision engine that analyzes transaction behavior, user patterns, and risk signals to approve or block payments within milliseconds. It combines machine learning models, rules engines, and streaming data pipelines to score every transaction before it clears.
When it works, customers never notice it. When it breaks through latency, drift, or poor data quality the entire payment experience degrades.
The Gap Nobody Talks About: Lab Conditions vs. Production Chaos
In a lab environment, data is static, labeled, and clean. In production, it's a high-velocity stream of noisy, incomplete, and constantly shifting inputs across US payment ecosystems processing millions of card transactions daily.
A typical fraud detection system looks clean on paper: transactions stream in via APIs, features get extracted, models score risk, alerts fire. But each of those steps carries hidden failure modes that only surface under real load and PCI-DSS compliance requirements mean there's no room for gaps.
The model is not the problem. The data pipeline is.
If your false positive rate exceeds 15%, your data architecture needs a redesign not just a model retune.
When This Becomes a Business-Critical Problem
Decision-makers often ask: is this my problem right now, or later?
Here are the signals that make this urgent:
Fraud false positives exceed 10–15% of flagged transactions
Payment approval rates are dropping month-over-month without a clear fraud explanation
Model retraining frequency is increasing but performance keeps declining
New geographies or payment methods have been introduced (new rails alter baseline behavior your model learned)
Chargeback cycles typically 30–60 days in US payment networks are creating labeling lag that corrupts your training data
If two or more of these apply, the problem is architectural not a modeling issue you can tune your way out of.
4 Reasons Fraud Detection Models Fail After Deployment
| Problem | What Happens | Business Impact |
|---|---|---|
| Data Drift | Model patterns become outdated as fraud evolves | Accuracy drops 20–40% within months |
| Latency | Pipeline delays push decisions past 200ms | Lost transactions, abandoned checkouts |
| False Positives | Legitimate users get blocked | Conversion drops 40%, customer churn rises |
| Scalability | Systems overload at 10k+ TPS | Revenue risk, system downtime |
1. Data Drift The Silent Model Killer
Fraud evolves. Fraudsters adapt faster than retraining cycles. The model you trained six months ago was built on yesterday's fraud patterns.
Concept Drift occurs when fraud tactics change for example, account takeover via social engineering replacing credential stuffing. Model accuracy can drop 20–40% within months without any change in your data pipeline.
Feature Drift happens when input distributions shift such as new payment rails altering transaction velocity norms that models had learned to treat as suspicious.
Label Drift emerges when ground truth labeling lags behind actual fraud. In US payment networks, chargeback cycles of 30–60 days mean models keep learning from stale, incorrect labels.
Population Drift occurs when your user base expands into new geographies or demographics with sparse historical data, causing models to amplify bias in underrepresented segments.
Without automated drift detection using metrics like PSI (Population Stability Index) or KS-tests, fraud risk management becomes entirely reactive.
2. Latency Where Milliseconds Cost Real Money
Payment fraud detection requires decisions in under 100 milliseconds. Beyond that, you're either blocking legitimate transactions or introducing friction that kills conversion.
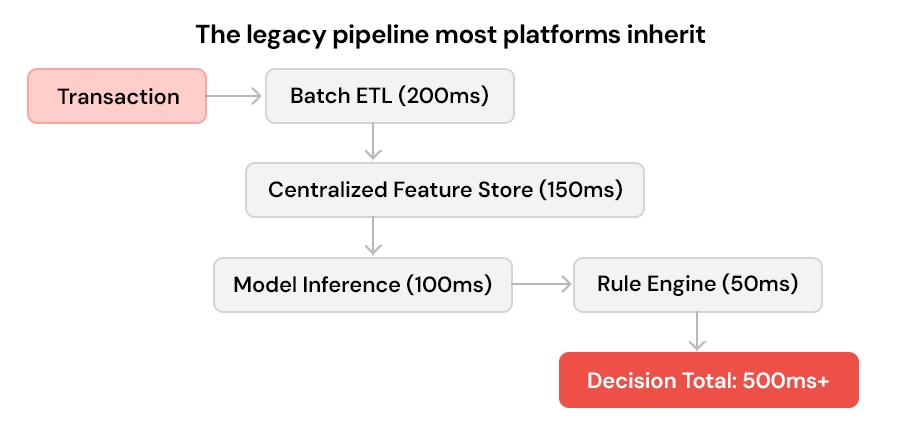
The legacy pipeline most platforms inherit:
An optimized, streaming-first architecture:
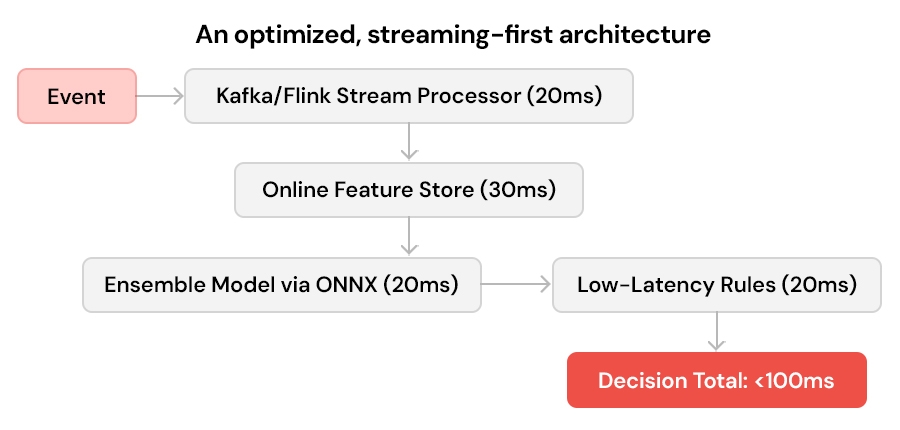
If your pipeline latency exceeds 200ms, you're losing transactions and customers may not come back.
3. False Positives The Customer Experience Tax
A fraud detection model that flags 1 in 10 legitimate transactions creates a 40% cart abandonment rate in payment flows. The model looks like it's working it's catching fraud but it's quietly destroying your conversion funnel.
Root causes include imbalanced training datasets that over-index on fraud signals, threshold settings optimized for recall rather than precision, and absence of human-in-the-loop feedback that would help the model learn from production mistakes.
4. Scalability Limits at High Transaction Volume
Monolithic feature stores and centralized databases hit hard limits at 10,000+ transactions per second. Cold-start problems where new users or merchants have no behavioral history create blind spots that fraudsters actively exploit in high card transaction volumes common across US payment ecosystems.
Most teams don't have dedicated ML infrastructure teams, which makes these issues harder to detect early and much more expensive to fix once they compound.
Where Fraud Detection Pipelines Actually Break in Production
Most fraud detection failures happen in ingestion, feature engineering, and model serving not in the model itself.
The fraud detection in fintech pipeline has six stages, each with a distinct failure mode:
Ingestion (Kafka/Kinesis): Event drops of 5–10% are common under peak load, meaning real fraud goes undetected by default.
Validation and Enrichment: Null values, duplicate events, and schema mismatches from external APIs corrupt the feature inputs models depend on.
Feature Engineering (Spark/Beam): Compute-intensive transformations create bottlenecks that cascade into latency spikes downstream.
Storage (Offline: Delta Lake/S3; Online: Redis/Feast): Staleness greater than one hour in online stores means models score risk on outdated behavioral context.
Model Serving (Seldon/Triton): Version mismatches between training and serving environments silently degrade model performance.
Monitoring and Feedback: Without active drift alerts and feedback loops, failures compound undetected for weeks.
Two clear signals your pipeline has structural issues not just model issues:
If onboarding new merchants takes weeks to reflect accurately in fraud scoring → architecture issue
If fraud rules keep increasing but detection accuracy doesn't improve → pipeline issue
If you're seeing rising false positives or latency spikes, retraining the model won't fix it.
Schedule a 30-Min Architecture Review →
Fraud Detection Architecture Best Practices That Actually Work
1. Hybrid Data Layering Match Storage to Use Case
Effective payment fraud detection architectures use three layers working in parallel:
Offline Layer uses Delta Lake for historical training data, enabling ACID transactions and time-travel queries for model retraining and compliance audits.
Online Layer uses real-time feature stores like Feast or Tecton for sub-50ms lookups that serve live model inference without latency penalties.
Graph Layer uses Neo4j or similar for entity resolution connecting accounts, devices, and merchants to surface fraud rings that transaction-level models miss entirely.
2. Streaming-First Processing Stop Batch Thinking
Batch ETL is incompatible with real-time fraud risk management. Apache Flink and Kafka Streams enable windowed aggregations velocity checks, behavioral baselines, anomaly signals computed continuously rather than on a delay.
This is particularly important for detecting burst fraud patterns, where attackers test stolen credentials across hundreds of transactions within a five-minute window before any batch job would flag the activity.
3. Ensemble Modeling with Continuous Learning
No single model type handles all fraud patterns. Production-grade fraud detection systems use ensembles that combine complementary strengths:
Tree-based models (XGBoost) handle structured transaction features efficiently. SHAP values make outputs defensible for compliance and investigation teams.
Neural networks capture sequential patterns across sessions critical for detecting account takeover scenarios that play out across multiple low-risk steps before a high-value action.
Graph Neural Networks identify mule account networks and synthetic identity rings by analyzing relationships across entities, not just individual transactions.
Rules engines sit downstream for deterministic overrides on high-value alerts where model uncertainty is too high to rely on probability alone.
Automated retraining triggered by PSI thresholds rather than calendar schedules keeps these models current with evolving fraud tactics.
4. Observability That Catches Problems Before Customers Do
Transaction monitoring systems need more than accuracy metrics. Production observability requires Precision@K and P99 latency tracked continuously, KS-test-based drift alerts that fire before model degradation becomes visible in fraud rates, and active learning pipelines that route edge cases to human reviewers whose labels feed back into model training.
Without this feedback loop, models drift toward irrelevance while dashboards still show green.
How One Payments Platform Reduced False Positives from 25% to 8%
A mid-sized payments provider processing regional transactions was experiencing a 25% false positive rate. Operations costs were climbing. Customer complaints about blocked transactions had become a weekly escalation.
The root cause wasn't the model it was a batch ETL pipeline introducing 4-hour feature staleness into a model that expected near-real-time behavioural context.
By migrating to a Flink-based streaming pipeline with Feast for online feature serving, and deploying an ensemble combining their existing gradient boosting model with a graph-based mule detection layer, they brought false positives down from 25% to 8% and cut latency by 70% within a single quarter.
The rebuild was accelerated by engaging product engineering services with FinTech-specific expertise used by FinTech teams handling high transaction volumes compressing a 9-month internal roadmap into 12 weeks through parallel workstreams across Software Product Development, Cloud and DevOps Engineering, and model deployment.
Why Most Teams Struggle to Fix This Internally
Fixing fraud architecture requires coordination across data engineering, infrastructure, and product teams simultaneously which most teams are not structured to do.
Each team owns a piece of the problem, but nobody owns the full pipeline. Data engineers optimize for throughput. ML teams optimize for accuracy. Infrastructure teams optimize for cost. The gaps between these functions are exactly where production failures live.
Product Strategy & Consulting defines the architecture roadmap upfront, balancing fraud performance against infrastructure cost and regulatory requirements including PCI-DSS alignment before a line of code is written.
Product Design and Prototyping enables rapid validation of new fraud detection approaches testing streaming architectures or new feature sets before committing to full-scale implementation.
Software Product Development builds the custom pipeline components that off-the-shelf tools don't cover, particularly in the feature engineering and model serving layers where FinTech requirements diverge from generic ML platforms.
Cloud and DevOps Engineering provides the CI/CD infrastructure for continuous model deployment ensuring retrained models reach production in hours rather than weeks, with immediate rollback when performance degrades.
For FinTech teams without dedicated ML infrastructure capability, engaging product engineering services early is often the difference between a system that scales and one that requires a full rebuild at Series B.
How to Fix Your Fraud Detection Architecture (Step-by-Step)
Most teams try to fix models first. The real fix starts with architecture and most streaming and feature store implementations can be completed in 8–12 weeks with the right approach.
Step 1 Audit your current pipeline. Map each stage against the failure modes above. Measure actual latency, event loss rates, and feature staleness before making any architectural decisions.
Step 2 Migrate to streaming. Move the most latency-sensitive feature computation to Kafka or Flink first. Identify the features driving your worst latency and start there you don't need to rebuild everything at once.
Step 3 Deploy an online feature store. Open-source Feast is a viable starting point for most teams. The goal is to decouple feature serving from model inference so each can scale independently.
Step 4 Implement ensemble modeling. Add a rules layer downstream from your primary model before investing in more complex architectures. The improvement from deterministic overrides on high-value transactions is immediate and measurable.
Step 5 Instrument drift detection. Set PSI thresholds for your top 20 features. Trigger retraining automatically when thresholds are breached not on a monthly schedule.
Step 6 Build feedback loops. Connect analyst review outcomes back to training data. Models that learn from production edge cases consistently outperform those trained only on historical datasets.
The Bottom Line
Fraud detection model failures in production are almost always data architecture failures in disguise.
The model is a passenger. The pipeline is the vehicle and if the vehicle is broken, the best model in the world won't get you where you need to go.
Fraud risk management at scale requires streaming-first pipelines, hybrid storage architectures, ensemble models with continuous retraining, and observability that surfaces problems before customers feel them.
The platforms that get this right don't just reduce fraud losses. They reduce operational overhead, improve conversion rates, and build the kind of payment processing system trust that compounds into long-term customer retention.
If your false positives are climbing, your latency is spiking, or your model performance has degraded since deployment the problem is almost certainly in your data pipeline, not your model weights.
Improve Fraud Accuracy Without Slowing Payments




