



Artificial intelligence has grown exponentially in recent years, with deep learning emerging as an innovation source for many of the fields, including NLP, computer vision, and speech recognition. And, as a consequence of such progress, many very specialized models have appeared that are experts in specific tasks like language translation, object recognition, or even creative performances in generating art and music. One of the probably most revolutionary innovations in AI is multimodal AI, in which models are created to perceive and integrate information from different types of data: images, text, and sound.
This blog explores the advent of multimodal AI—the ability to blend vision with language and the underlying technologies, applications, challenges, and potential uses of this field, which is growing at a breakneck pace. As this innovation continues to shape industries, ai development services play a crucial role in designing and implementing these advanced solutions.
What is Multimodal AI?
By definition, multimodal AI systems process and integrate data from multiple modalities to accomplish the tasks that require comprehensiveness in knowledge around the world. Traditional AI models often are unimodal, that is, they focus on a special kind of input data. For example, while an NLP model such as GPT is optimised for text-oriented tasks, computer vision models, such as ResNet, are optimised for image recognition. Multimodal AI would help cross the boundary between these domains to yield more robust, nuanced, and contextually aware models.
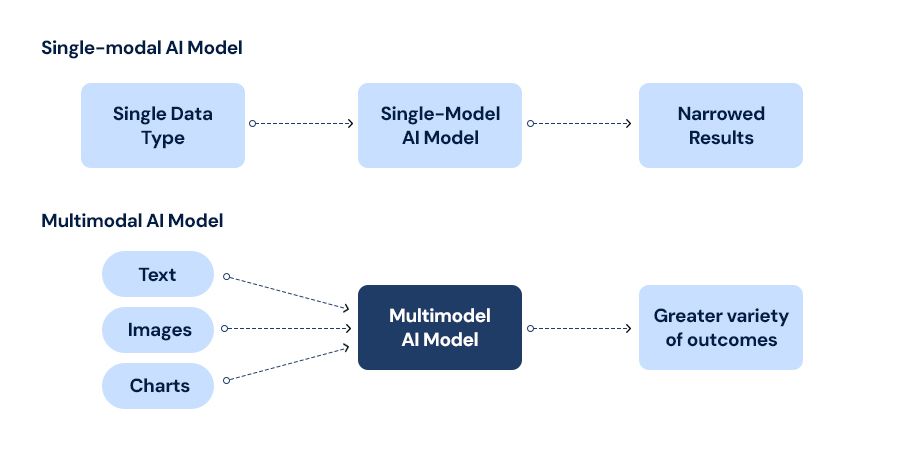
AT the heart of multimodal AI lies the confluence of language and vision-two of the most outstanding sensory modalities in human cognition. In that sense, combining them can lead an AI system to a more enriched understanding of the world.
How Does Multimodal AI Work?
Therefore, one of the big challenges in building multimodal AI concerns the combination of mutually intrinsically very differently structured data types. Images are represented as arrays of pixels while the text is represented as discrete tokens. Advanced machine learning techniques, such as :
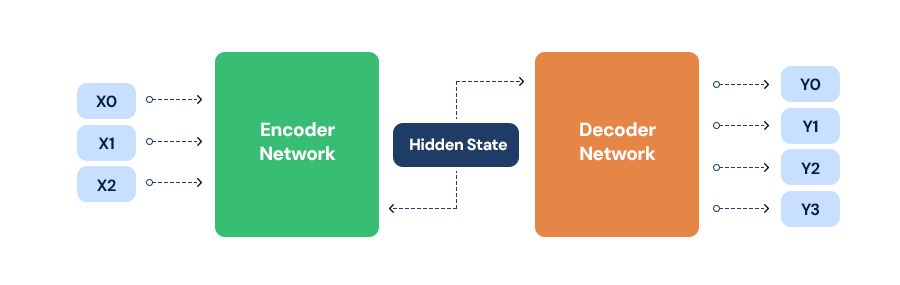
Encoders and Decoders : These are two types of functions that accept input data like an image or text in a uniform format proper for inputting into neural networks. Now, decoding this information back to some special modality is the function of the decoder. For example, in tasks like image captioning, the visual information is processed by the encoder and textual descriptions are produced by the decoder.
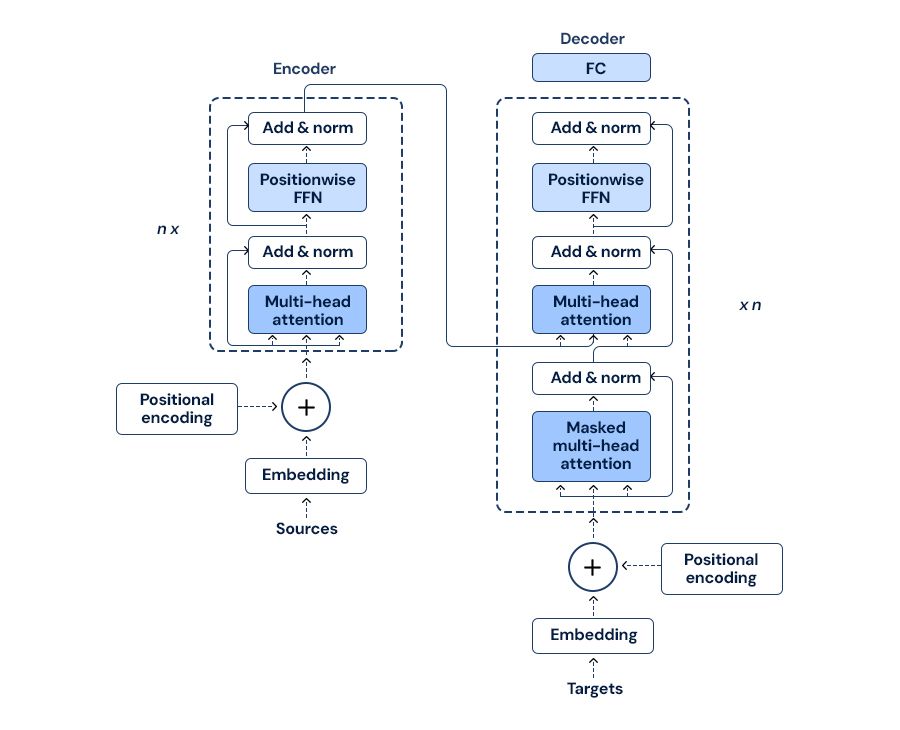
Transformers:- are playing a vital role in multimodal models, particularly in the form of ViT and the sequence of transformers in the case of language transformers (like BERT, GPT). In a way, transformers can handle sequential data and therefore rightly apply to language, and even image processing, and transformers are aligned representations in the case of various modalities.
Cross-Attention Mechanisms :- Cross-attention mechanisms ensure models allow the possibility of concentrating on important elements of either an image or sentence as they process them together. For instance, in the question answering system whose input is images, that would imply the model uses cross-attention to focus relevant parts of the image while interpreting a question.
Feature Fusion :- The feature fusion techniques include through concatenation, addition, or even more complicated fusion methods like bilinear pooling. So, the model deciphered through combining features from both visual and textual modality.
Which difficulties face during Multimodel:
Our customer faces significant hurdles with manual invoice processing, which impacts efficiency and scalability. The manual process is labor-intensive, error-prone, and results in time-consuming workflows and financial discrepancies. Creating a standardized extraction solution can be tough as invoice layouts vary across industries. Unstructured data like layout-independent data further complicates things. Manual data extraction errors cause payment delays, operational disruptions, and compliance risks, so robust security measures are needed. As our customers scale, existing manual processes struggle to manage increasing invoice volumes, causing bottlenecks and decreased agility.
To address these challenges, the client aims to streamline invoice processing through automation and advanced technologies. Partnering with an AI development company, they plan to implement AI-powered solutions to enhance data accuracy, mitigate operational risks, and support regulatory compliance. By leveraging innovative technologies, our customer seeks to optimize financial processes, improve scalability, and ensure efficient management of growing invoice volumes, ultimately driving operational excellence and enabling sustainable business growth.
Key Applications of Multimodal AI
The integration of vision and language has led to breakthroughs in several domains, including:
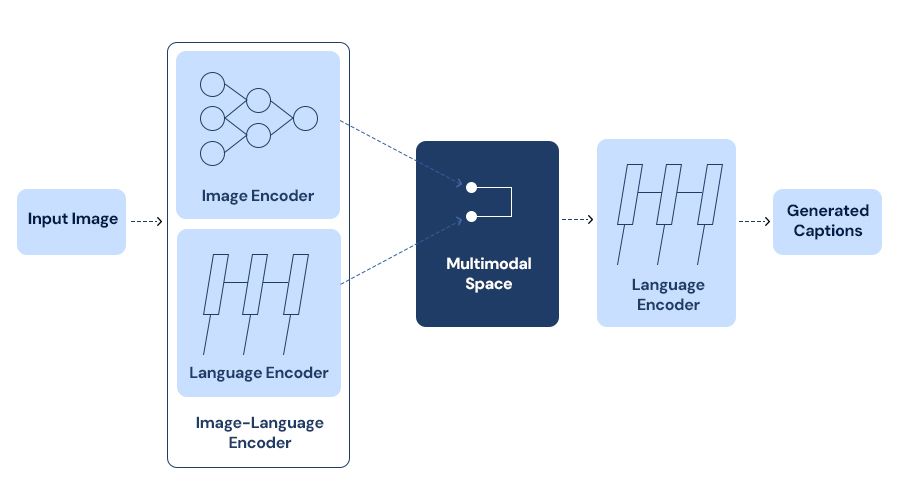
Image Captioning :- One such very interesting application of multimodal AI is perhaps image captioning: the ability to produce descriptive textual captions for images. Such models, especially the OpenAI CLIP and DALLE models, combine computer vision and language models so they can generate captions or even create images from text descriptions. This has huge-ranging implications for social media, content creation, and accessibility.
Visual Question Answering (VQA) :- VQA is a question answering task where the model is exposed to a question of the given image, and it has to come back with a textual answer based on what it has derived from the visual content. For example, given an image of a park, a model may be asked "How many people are there in the park?" The system needs to understand both the image and the question for it to come up with a proper answer. Applications of VQA are commonly deployed within educational training, customer service, and autonomous systems.
Multimodal Search Engines :- It has also changed the nature of search engines whereby both images and text can be input by a user to find something. Such as an ability of uploading an image of something with the description of what it is in text words and finding similar items. This maximises the accuracy of the information and personalizes the content received. Early adopters include Pinterest and Google Lens.
Autonomous Vehicles :- Autonomous vehicles employ multimodal AI to combine vision information, including camera data, with a stream of language, such as route instructions, and sensory data, including LIDAR and radar. Multimodal AI then combines all this information for real-time navigation and decision-making. They must understand visual clues, such as traffic signs, following commands in the natural language or even communicating with other AI systems.
Healthcare :- This kind of AI is hugely applied in health care scenarios, such as in medical imaging and diagnosis. For example, an AI system can scan medical scans and patient records-the medical scans include X-rays or MRIs-in combination with the patient's text to aid doctors in diagnosing a disease. It integrates the knowledge or understanding of a patient's condition for more accurate diagnoses and treatments in the future based on treatment profiles.
Challenges Faced in Building My Multimodal Model :
While multimodal AI offers incredible potential, it also comes with a set of challenges:
Manual Invoice Processing :- The primary challenge for our fintech customer is the reliance on manual invoice processing methods, which are time-consuming, labor-intensive, and prone to errors. This manual approach leads to operational inefficiencies, including delays in processing invoices and an increased risk of financial discrepancies.
Layouts of Invoice :- Facing the challenge of handling diverse document layouts, structures, and content across different industries. The variability in document formats makes it complex to develop a standardized extraction solution that can accurately interpret and extract data from all types of documents.
Dealing with unstructured data :- Dealing with unstructured data within documents, such as handwritten notes or unconventional formatting, presents a significant limitation. Extracting information accurately from less structured or non-standardized documents requires advanced techniques and continual refinements.
Security and Compliance Concerns :- Security and compliance are critical considerations due to the sensitivity of invoice data. Our fin tech customer must implement robust measures to protect confidentiality and ensure adherence to regulatory requirements, adding complexity to the invoice processing workflow.
Scalability Issues :- As the business scales and invoice volumes increase, existing manual processes struggle to cope efficiently. This leads to bottlenecks, decreased operational agility, and challenges in managing growing invoice volumes without compromising performance.
Operational Disruptions :- The inefficiencies and errors associated with manual invoice processing contribute to operational disruptions within the organization. These disruptions impact overall workflow efficiency and customer service delivery.
DocuTranscribe Aspire SoftServ’s Solution in Multimodal AI:
Our proposed solution is AI-Powered DocuTranscribe which is a cutting-edge SaaS (Software as a Service) technology designed to revolutionize invoice processing. DocuTranscribe supports many features such as scanning any invoices and extracting the data to the desired format, processing bulk invoices, being easy to integrate with 3rd party solutions, VEGA learning over time, supporting multiple languages, and user-friendly UI/UX. On the other hand, it improves invoice handling tasks, improving operational efficiency and productivity while achieving significant cost savings.
The following are the key features
Scalability: Scalable architecture optimized for handling increasing volumes of processed invoices without compromising performance or efficiency.
The DocuTranscribe empowers users to upload and process both single and multiple documents in a single run, offering flexibility based on the company's specific data processing requirements. This user-friendly approach allows businesses to tailor their document uploads according to the volume of data they need to process efficiently within a given time frame. Whether processing a single invoice or batches of invoices simultaneously, the solution adapts to varying workloads, accommodating diverse business needs seamlessly. This capability enhances operational efficiency by providing a scalable and adaptable platform that aligns with the dynamic processing demands of modern enterprises.
Layout Independent Extraction:-To overcome the challenge of diverse invoice layouts and structures, our solution involves developing a layout-dependent parser using advanced Natural Language Processing (NLP) and Optical Character Recognition (OCR) techniques. This innovative approach enables the parser to intelligently interpret and extract data from invoices with varying formats and layouts. By leveraging NLP for semantic understanding and OCR for accurate text extraction, the system can identify key invoice elements such as numbers, dates, and vendor details regardless of layout complexity. Additionally, implementing a machine learning-based parsing model ensures adaptability and continuous improvement over time, enhancing accuracy and efficiency in invoice processing workflows.
Our solution simplifies the document processing workflow by allowing users to select specific key elements they want to extract from invoices. Using our automated system powered by advanced technologies like Natural Language Processing (NLP) and Optical Character Recognition (OCR), users can choose desired data fields such as invoice numbers, dates, and vendor details. The solution then automatically retrieves and presents the selected keys from the documents, streamlining the extraction process and ensuring efficient data retrieval tailored to user preferences. This user-friendly approach enhances productivity and accuracy in invoice processing, providing a seamless experience for extracting targeted information from diverse document formats.
Unstructured Data Handling :- Ability to process unstructured data within invoices, including handwritten notes and unconventional formatting, with precision and efficiency.
Our solution offers a robust approach to handling unstructured data by enabling users to extract specific key information from documents efficiently. Using visualization and interpretability features, extracted values are displayed within bounding boxes alongside the annotated document. Users have the flexibility to modify key elements directly within these bounding boxes for easy customization. The extracted data is conveniently presented in a sidebar for verification, allowing users to review and ensure accuracy before downloading the data in preferred formats such as CSV or Excel. This streamlined process enhances data extraction, visualization, and usability, empowering users to leverage extracted information effectively for various business purposes.
Highly Accurate AI Predictions :- Utilisation of cutting-edge machine learning algorithms to achieve high accuracy rates in data extraction and interpretation, ensuring reliable insights from document content.
Seamless Integration :- Integration-friendly design that allows seamless connection with existing systems and software environments, enabling effortless implementation and compatibility.
Comprehensive Data Centralization :- Centralized storage and management of digitized invoice data, facilitating easy access, retrieval, and utilization for enhanced decision-making and operational transparency.
Conclusion
Multimodal AI comes as a revolution in which machines can see and understand the world in totally new ways. Bringing vision and language together, these models unlock new potential in medical applications and content creation and beyond. Even with all the remaining roadblocks, benefits from multimodal AI call for expecting how to construct AI systems that understand and reason about the world in ways closely comparable to those of humans.
As research in these areas continues to advance, the previously hard boundaries between vision, language, and other sensory modalities begin to dissolve, opening the door to building AI systems that are richer, more adaptable, and closer to human norms. The journey toward realizing this potential for multimodal AI is barely starting and promises to yield profound impact on society.
Learn More About Multimodal AI!




